


Rate Limiting System Design : Explained Simply
The Backend Guide to Building Scalable Rate Limiting

Rate limiting sounds simple — until you’re asked to design it in an interview or build it for millions of users.
This post breaks down how rate limiting actually works, step-by-step, without any fluff.
This is a high-level design meant for interviews or as a foundation to explore further in real systems.
What Are We Really Solving?
Before even touching code or system diagrams, let’s understand why rate limiting is needed.
Imagine this:
You’ve built an API that gives out weather data. It works fine for a few users. But one day, someone writes a bot that hits your API thousands of times per second. Your server:
Slows down
Crashes
Legit users can’t access it
Now multiply that with 10k users , some hitting it fairly, others abusing it and expensive backend services getting overloaded (like DB, external APIs).
That’s where rate limiting comes in.
Rate limiting helps you:
Protect your system from being overwhelmed.
Treat users fairly, no one should hog all the resources.
Control costs especially if you use third-party services with limits.
Block abuse, brute force login attempts, scraping, spamming.
Naive Approach — Limit in Code (Per Server)
Let’s say you try to solve it yourself. The first idea most devs have is:
“Let me just track how many requests a user has made in the last 1 minute.”
So you do something like:
Map<String, List<Long>> userRequests = new HashMap<>();Every time a request comes:
You log the current timestamp into
userRequests[userId].Then, you remove timestamps older than 1 minute.
Finally, you check if the list has more than 100 entries (i.e. 100 req/min).
Sounds simple?
But here’s what goes wrong:
Only works on a single server
If your system scales to multiple servers (as it should), one server might see 10 requests, another sees 90 — and both think it’s fine. So the user ends up sending 200 total.
Memory grows unbounded
If you keep timestamps per user, your in-memory list grows, especially for active users or attacks. You may run out of RAM.
No visibility
You can’t really monitor or audit who’s crossing limits, or why users are being blocked.
Time handling is flaky
Time-based logic like “remove old timestamps” can behave weirdly under heavy load, time drifts, or if system clock changes.
But this naive approach is still good for learning:
It helps you understand:
What rate limiting actually needs (tracking per user/IP/time window)
Why storage and coordination matter
Why choosing the right place to do it (code, middleware, proxy, etc.) is critical
Centralized Rate Limiter with Shared Store (e.g. Redis)
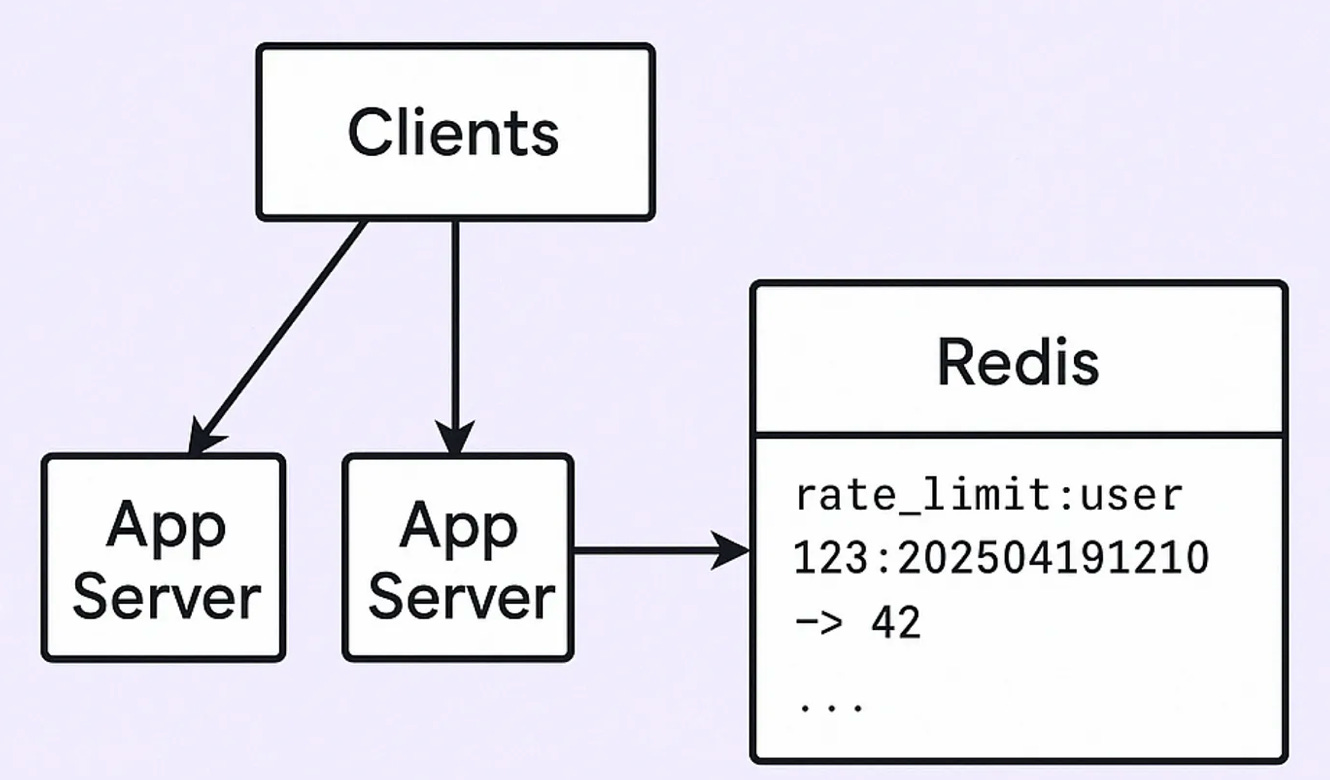
Now that we know the in-memory approach breaks in distributed systems, we need something that works across all servers.
Idea: Let’s store request counts in a shared place where all servers can read/write — like Redis.
Why Redis?
Fast (in-memory store)
Centralized — all app servers can talk to it
Supports TTLs — for auto-expiring counters
Atomic operations — so multiple servers don’t corrupt counters
How it works (Fixed Window Counter)
Let’s say you want to limit to 100 requests per user per minute.
Here’s the flow:
1. When a request comes in:
Your app checks Redis for a key like:
rate_limit:user_123:202504191210
(Here, 202504191210 = year + month + day + hour + minute = timestamped bucket)
2. If the key doesn’t exist:
Redis creates it and sets the value to 1
Also sets a TTL of 60 seconds
3. If the key exists:
Redis increments the value atomically
If it exceeds 100 → reject the request
Cool, you’ve implemented global rate limiting.
Why use TTL?
You don’t want to manually clean up keys. TTL handles expiry automatically:
After 60 seconds, Redis deletes the key.
Memory stays clean, limits reset every minute.
String key = "rate_limit:" + userId + ":" + currentMinute();
Long reqCount = redis.incr(key);
if (reqCount == 1) {
redis.expire(key, 60); // set TTL
}
if (reqCount > 100) {
rejectRequest();
}Issues with approach: Now even though Redis-based centralized rate limiting fixes a lot, it’s not perfect.
1. Bursts allowed at window edges
A user can hit:
100 requests at 12:00:59
100 again at 12:01:00
So effectively, they send 200 in 2 seconds.
Fix: Use sliding window or token bucket
2. Hot Keys in Redis
If one user (or attacker) makes a ton of requests, Redis might become a bottleneck for that key. Fix: Redis Cluster + key hashing
3. Atomicity required
Don’t read the key → increment in app → write back. Always use Redis commands like INCR or Lua scripts for atomic updates.
4. No Differentiation Between Users
You may want:
Free users: 60 req/min
Paid users: 1000 req/min
But Redis doesn’t know this by default.
Fix:
Encode limits in your code, not Redis
Or store per-user tiers in Redis (more complex)
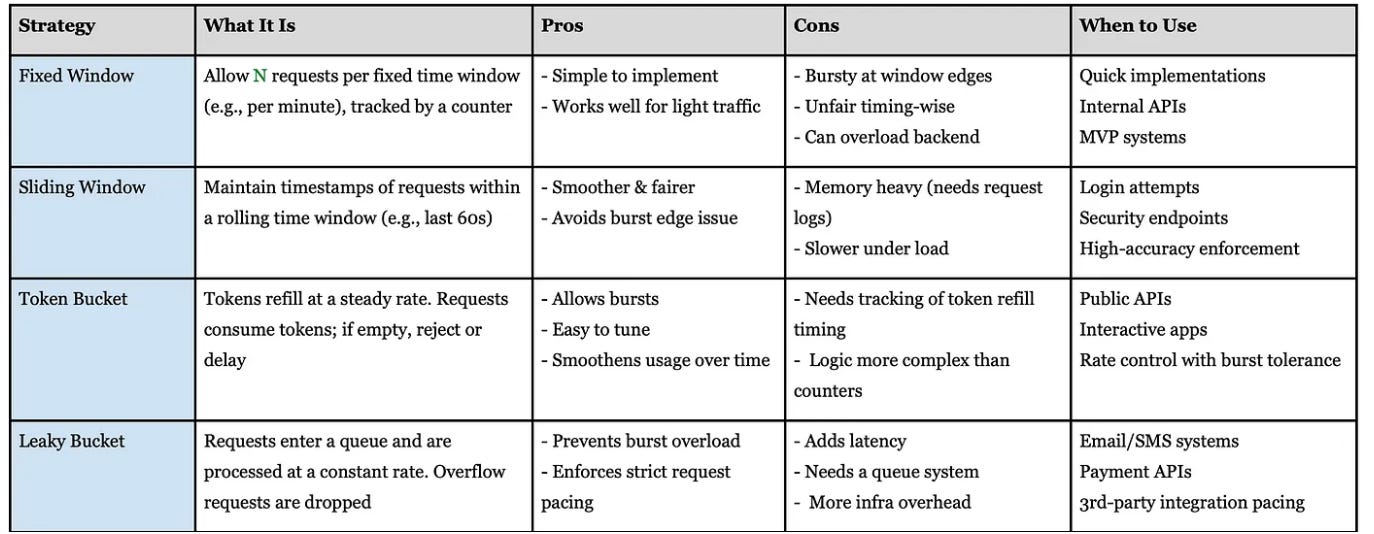
Smarter Rate Limiting Strategies — Comparison Table
Once you’ve got Redis or any shared store in place, you can implement more advanced strategies.
Scaling the Rate Limiter
Now you’ve got:
A central Redis-based rate limiter
Smarter algorithms like token bucket
But what happens when:
You get millions of users
Hundreds of microservices
Spiky traffic from all over the world?
Here’s how you scale the whole setup.
1. Redis Becomes the Bottleneck
Problem: All app servers are hitting Redis for every request → high QPS = Redis starts choking.
Solution: Redis Clustering / Sharding
Split keys across multiple Redis nodes
For example, keys like
rate_limit:user123andrate_limit:user456go to different shardsRedis handles distribution using key hashing
This gives horizontal scale.
2. Rate Limit by Region / Zone
Problem: If your users are global, latency to Redis (in a single region) is bad.
Solution:Geo-Distributed Rate Limiting
Deploy Redis near your app servers (e.g., US, EU, APAC)
Maintain region-specific limits
Optional: sync across regions (if needed) using pub/sub or replication (but tricky)
This lowers latency, avoids regional bottlenecks
3. Smarter Keys — Avoid Too Many Combinations
Problem: Tracking every combo like user+ip+endpoint+region → explosion of keys
Solution: Balance granularity
Track only what’s needed:
/loginmight need per-IP rate limit/searchmight need per-user
Use clear patterns in keys, like:
rate_limit:user:123
rate_limit:ip:123.45.6.7
rate_limit:user:123:endpoint:/searchKeeps Redis clean and predictable
4. Move Logic Closer to Edge (API Gateway Level)
Problem: If rate limiting happens in app code, bad requests already reach your app = waste of resources
Solution:Push Rate Limiting to Gateways / Proxies
API Gateway (e.g. Kong, Apigee)
NGINX with Lua + Redis
Cloudflare Workers (for global APIs)
These block requests before they reach your backend
Improves performance and security
5. Observability + Auto-Tuning
Problem: You don’t know who’s getting rate-limited, why, or how often
Solution:Add Monitoring + Logging
Log every rate limit breach with userID, endpoint, and timestamp
Export metrics to Prometheus + Grafana or Datadog, ELK, etc.
Helps in:
Alerting on abuse
Auditing users
Auto-adjusting limits (e.g. surge in traffic → relax limits temporarily)
6. Fallbacks: What If Redis Fails?
Problem: If Redis is down, entire API is at risk — either wide open or fully blocked
Solution: Graceful Degradation
If Redis unavailable:
Use a local in-memory backup limiter temporarily
Or fail requests with a clear error message
Make Redis highly available with sentinel/cluster/failover
Shows real-world readiness
Most people know what rate limiting is, but few can explain how to build and scale it right.
Mastering this one concept can instantly level up your system design answers and real-world backend skills.